
The English Brain of AI
How Language Bias is Shaping Global Intelligence

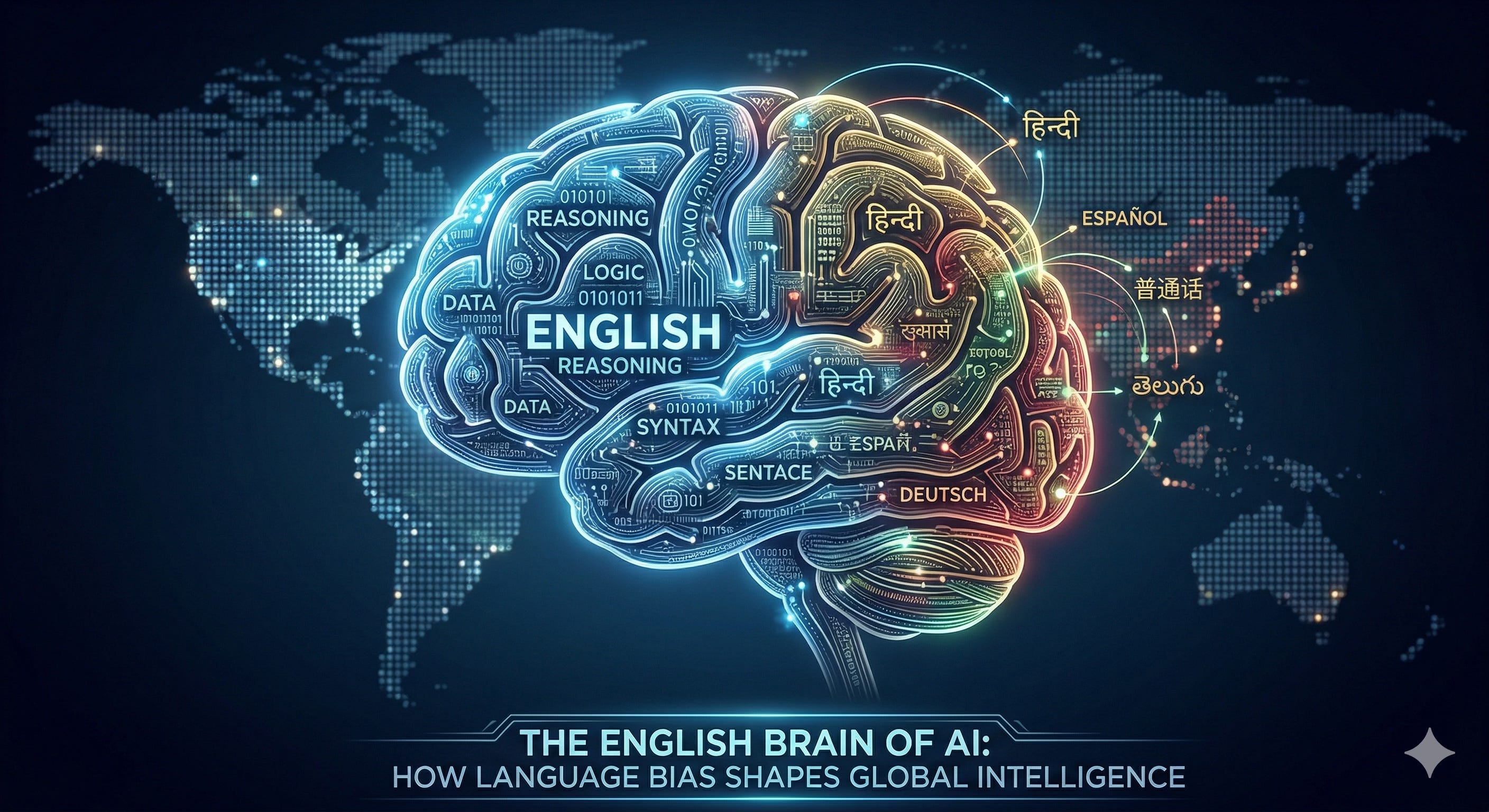
Artificial intelligence is often described as universal—capable of serving anyone, anywhere, in any language. But beneath this promise lies a structural imbalance.
Today’s leading AI systems—ChatGPT, Gemini, Claude, Llama—are not truly global intelligences. They are English-first systems with multilingual capabilities layered on top. And this distinction has real consequences for how knowledge is created, accessed, and trusted.
AI Doesn’t Just Speak English—It Thinks in It
Modern AI models are trained on internet-scale data, where English dominates. Around 50–55% of web content is in English, according to W3Techs [1], far exceeding its share of the global population of speakers. Large multilingual datasets, such as mC4, and models like mT5 also exhibit a strong skew toward English tokens [2].
The mC4 dataset, a multilingual variant of Google’s C4 corpus that includes text in 108 languages, demonstrates the scale of this disparity.While the dataset represents a significant effort toward multilingual inclusion, the token distribution reveals the depth of language inequality in AI training. English dominates with 2,733 billion tokens, while many other languages receive dramatically smaller allocations. For perspective, languages like Icelandic receive only 2.6 billion tokens despite serving 350,000 native speakers, while Telugu, spoken by 83 million people, has just 1.3 billion tokens. [15]
As a result, even when users ask questions in Hindi, German, or Spanish, models often rely on English-heavy representations and sources during processing.